The landscape of large language models just shifted. As of March 2026, Anthropic has officially moved its 1M token context window into general availability for both Claude Opus 4.6 and Claude Sonnet 4.6.
While previous iterations like Sonnet 3.5 or 4.0 toyed with large windows, the 4.6 generation marks the first time the flagship Opus model can ingest up to a million tokens—roughly 750,000 words—in a single request. But with great context comes significant costs and architectural nuances that every developer and enterprise leader needs to understand.
The 1M Breakthrough: Why It’s Different in 2026
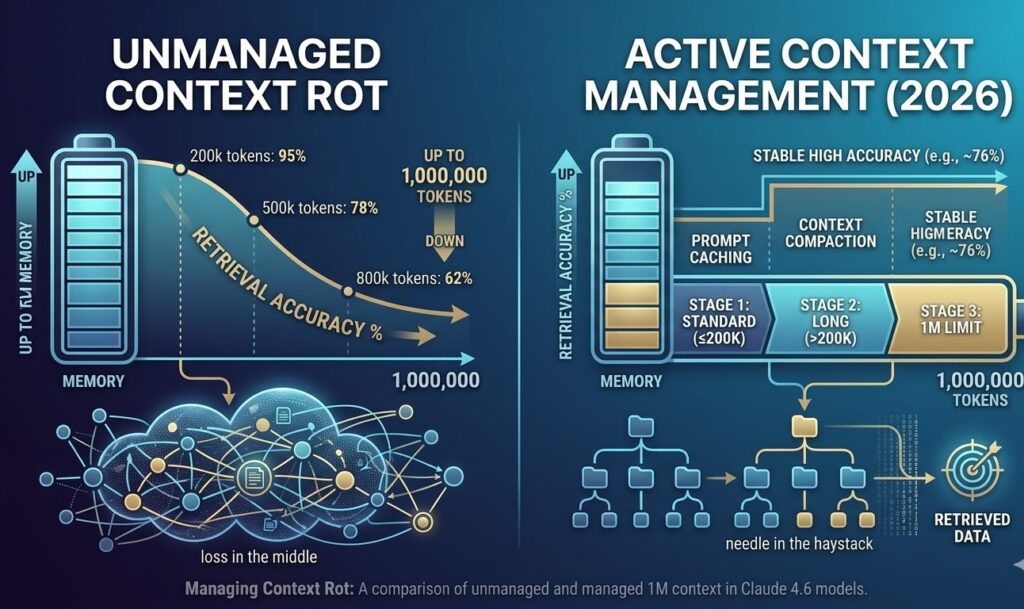
In 2024, a “large” context window was 128k tokens. In 2026, 1M tokens is the new baseline for professional-grade AI. This update isn’t just about “more memory”; it’s about retrieval accuracy.
Anthropic’s latest benchmarks for Opus 4.6 show a qualitative leap in performance:
- MRCR v2 (Multi-needle Retrieval): Opus 4.6 achieves 76% accuracy at the full 1M token limit.
- Context Compaction: A new 2026 feature that automatically summarizes older parts of a conversation to prevent “context rot” (performance degradation) as you approach the 1M limit.
Key Takeaway: Unlike previous models that became “lazy” or “hallucinatory” after 200k tokens, Opus 4.6 is designed to maintain logical coherence across entire codebases or 20+ research papers.
Opus 4.6 vs. Sonnet 4.6: Which One Should You Use?
While both support the 1M window, their internal architectures and pricing differ significantly.
| Feature | Claude Opus 4.6 | Claude Sonnet 4.6 |
| Best For | Deep reasoning, complex refactors | Speed, high-volume agents |
| Pricing (per 1M tokens) | $15 Input / $75 Output | $3 Input / $15 Output |
| Max Output Tokens | 128K | 64K |
| Latency | Moderate (Adaptive Thinking) | Fast (~50 tokens/sec) |
| Special Features | Adaptive Thinking, Agent Teams | High Breadth-First Accuracy |
When to choose Opus 4.6:
Choose Opus for depth-first tasks. If you are refactoring a massive legacy codebase or conducting multi-hop legal analysis where missing one detail is a “fail,” the Opus premium is worth it. It currently leads the industry with a 91.3% score on GPQA Diamond (expert-level reasoning).
When to choose Sonnet 4.6:
Choose Sonnet for breadth-first tasks. Interestingly, 2026 benchmarks show Sonnet 4.6 actually outperforms Opus in finding a high volume of surface-level bugs in large PRs, and it does so at 80% lower cost.
Pricing & The “Long-Context Premium”
Managing costs in the 4.6 era requires a new strategy. Anthropic has introduced a tiered pricing model for the 1M window:
- Standard Window (≤ 200K tokens): $5.00 Input / $25.00 Output.
- Long-Context Window (> 200K tokens): Pricing can scale up to $10.00/$37.50 per million tokens depending on the API tier.
- Prompt Caching: Essential for 2026. By caching your 1M token codebase, you can save up to 90% on repetitive input costs.
Practical Applications for 1M Tokens
1. Software Engineering at Scale
With 1M tokens, you no longer need to pick and choose which files to show Claude. You can feed in the entire repository. Opus 4.6’s “Agent Teams” feature allows it to spawn sub-agents that review different modules simultaneously while keeping the full architectural context in mind.
2. Legal and Compliance Discovery
A million tokens is enough to hold 10–15 full-length legal contracts. Opus 4.6 can perform cross-document contradiction checks that were previously impossible without complex RAG (Retrieval-Augmented Generation) pipelines.
3. “Vibe Coding” & Rapid Prototyping
As seen in recent community tests, Sonnet 4.6 can build entire functional MVPs—like a Tower Defense game—in a single shot. The large window allows the model to “remember” the state and UI requirements without you having to re-explain the rules every three prompts.
How to Manage “Context Rot”
Even with 1M tokens, AI can suffer from “loss in the middle.” Here are three expert tips for 2026:
- Use Adaptive Thinking: Set your
effortparameter toHighorMaxwhen processing over 500k tokens. - Implement Compaction: Use the API’s automatic compaction blocks to prune “chat noise” while keeping technical data fresh.
- Multi-Needle Checks: If your data is critical, ask the model to “list the 5 most relevant sections” before asking for the final analysis to prime its internal attention mechanism.
Conclusion: Is 1M Context the New Standard?
The availability of 1M context for Opus 4.6 and Sonnet 4.6 represents a pivotal moment. We have moved from “Chatting with a Doc” to “Collaborating with a Repository.” While the costs are higher, the efficiency gains for senior developers and researchers are undeniable.
Have you successfully run a 1M token prompt yet? Share your latency results and “needle” accuracy in the comments below!